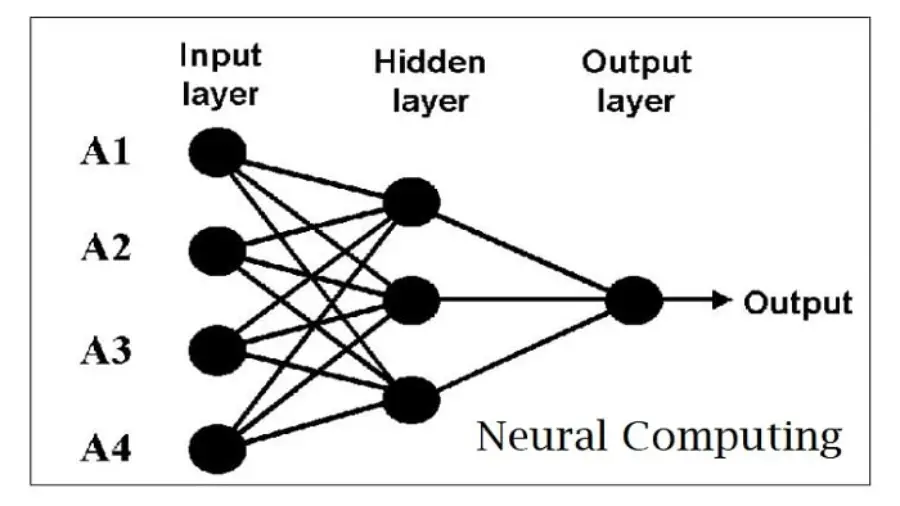
Neural computing is a branch of artificial intelligence that deals with the design and development of algorithms that simulate, emulate, or otherwise harness the computational power of biological neural systems. The term “neural computing” is often used interchangeably with “connectionist computing,” as both approaches are based on the same underlying principle: that complex patterns can be learned by interconnected networks of simple processing units. There are several different methods of neural computing, each with its strengths and weaknesses. Which of These Analysis Methods Describes Neural Computing? You’ll get here details about the topics.
There are several methods of neural computing, all designed to help machines better understand and process data. The most common methods are artificial neural networks (ANNs), support vector machines (SVMs), and deep learning. Each method has its own strengths and weaknesses, so choosing the right one for your needs is important.
About Artificial Neural Networks
ANNs are perhaps the most well-known method of neural computing. They are inspired by the brain, and can simulate its workings to some degree. ANNs are good at pattern recognition and can be used for tasks such as image classification.
However, they can be slow to train, and sometimes struggle with more complex problems. SVMs are a powerful tool for many different machine learning tasks. They work by mapping data points into a high-dimensional space, then finding a hyperplane that divides them into two groups.
SVMs are very effective when there is a clear separation between the two groups of data points. However, they can be less accurate when the data is more noisy or overlapping. Deep learning is a relatively new field of machine learning that has been gaining popularity in recent years.
Deep learning algorithms learn from data in multiple layers, each layer extracting higher-level features from the previous one. This allows them to solve problems that were once considered too difficult for machines, such as natural language processing and computer vision.
Credit: www.nature.com
What is Neural Computing?
Neural computing is a branch of artificial intelligence that deals with the design and development of algorithms that can learn from data. Neural networks are a type of algorithm that are designed to mimic the way the brain learns. They are used to recognize patterns, cluster data, and make predictions.
What are the Main Methods of Neural Computing
Neural computing is a field of computer science and engineering focused on developing systems that can learn and perform intelligent tasks similar to those performed by the human brain. Neural computing systems are based on artificial neural networks (ANNs), which are modeled after the brain’s structure and function. There are three main types of neural networks: supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning is where the system is trained with a set of input-output pairs so that it can learn to map inputs to outputs. Unsupervised learning is where the system is only given inputs and must learn to find patterns and relationships in the data itself. Reinforcement learning is where the system interacts with an environment and learns from its actions and experiences.
Each type of neural network has its strengths and weaknesses, but all three can be used for various applications such as pattern recognition, classification, prediction, control, etc.
How Does Neural Computing Work?
Neural computing is a branch of artificial intelligence that deals with the design and development of algorithms that can learn from and make predictions on data. Neural networks are a type of algorithm that are used in neural computing. They are modeled after the brain and consist of a series of interconnected nodes, or neurons, that can process information.
Neural networks are trained using a set of training data. The network adjusts the connections between the nodes based on this data so that it can better predict the outcomes for new data. This process is called learning or training.
Once a neural network has been trained, it can be used to make predictions on new data sets.
For example, a neural network might be trained on financial data in order to predict stock prices. After being given a set of training data, the network would adjust the connections between the nodes so that it could better identify patterns in the data.
Once trained, the network could then be used to predict stock prices for new days or weeks.
Neural networks have been used for various tasks such as image recognition, speech recognition, and even playing games such as Go and chess.
What are Some Applications of Neural Computing
Neural networks are a type of machine learning algorithm that are used to model complex patterns in data. Neural networks are similar to other machine learning algorithms, but they are composed of a large number of interconnected processing nodes, or neurons, that can learn to recognize patterns of input data. Neural networks have been used for many years to solve problems in areas such as image recognition and classification, natural language processing, and fraud detection.
Neural networks are used in a variety of ways, including:
1. Pattern recognition
Pattern recognition is the ability to identify a particular type of pattern in data. This might be something as simple as recognizing a familiar face or remembering an address. Generally speaking, it’s one of the key skills that you need for many different industries, including marketing and web development.
One example of how this skill could be used in web development is template detection. When preparing or updating website content, it can be helpful to automatically replace certain stock images with custom images that match your site’s design style. By using machine learning algorithms, you can detect which templates are being used on a given page and display the corresponding image instead.
This technology also has applications in SEO (search engine optimization). By recognizing common search terms and phrases across various websites, you can improve your position on Google pages by incorporating those keywords into your content appropriately.
Pattern recognition is the ability to automatically recognize a pattern or decor in an object, scene, or environment. This can be helpful for tasks such as navigation and recognizing objects in pictures. It can also play a role in people’s daily lives by helping them with physical tasks like picking out clothes or steering their car.
The brain uses several different processes to recognize patterns, including visual processing (seeing), auditory processing (hearing), and somatosensory processing (touch). Some of the most common abilities that are related to Pattern recognition involve vision and shape discrimination. Visual memory involves storing information about how things look so that it can be recalled later. Shape discrimination helps us identify simple shapes like squares and circles from more complex ones, such as triangles and stars.
2. Data classification
Data classification is the process of grouping data according to specific criteria so that it can be more easily understood and processed. This can be done manually or through automated methods, and it is an essential part of data management. When data is properly classified, it becomes easier to find information and make decisions based on the information’s content.
It is the process of dividing data into categories and subcategories in order to make it more manageable. This can be useful when organizing and analyzing your data, as well as making decisions based on that information. It can also be used for reporting purposes or for creating
3. Data prediction
Data prediction is the ability to anticipate trends or patterns in data that may impact business decisions. By understanding these trends, you can make more informed choices about your marketing and operational strategies.
Some of the ways that data prediction can be used include forecasting customer demand, predicting sales performance, and anticipating changes in product preferences. Predictive modeling is also an important tool for detecting fraud or abuse before it becomes a problem.
Data prediction is an essential part of any successful business operation, so make sure to keep up with the latest techniques and standards when it comes to collecting, storing, analyzing, and sharing data.
This can be done by analyzing trends, measuring correlations between different variables, and understanding how Patterns emerge over time. By using this information, you can develop models that will allow you to anticipate upcoming changes with greater accuracy.
This type of predictive analysis can be used for a variety of purposes, from forecasting sales numbers to anticipating voter behavior. By applying data-driven reasoning techniques in your business decisions and marketing strategies, you can achieve better outcomes more consistently than ever before.
There are other related contents these are on What Do You Give a Dog That Loves Computers? and How to watch Khmer TV on a Computer?
Neural Network Architectures & Deep Learning
These errors can then propagate through the organization if they go undetected. Finally, self-service analytics can also put strain on organizational resources. If every team within a company is using its own self-service tool, this can require a lot of training and support from IT or data analyst staff.
Which of the Following is a Potential Disadvantage of Self-Service Analytics?
There are many potential disadvantages of self-service analytics. One such disadvantage is that it can lead to data silos. When different teams within an organization start using different self-service analytics tools, it can be difficult to share data and insights across the organization.
This can lead to each team having its own version of the truth, which can make it difficult to make decisions at a company-wide level. Another potential disadvantage of self-service analytics is that it can increase the risk of errors. Since users are able to access and analyze data without any oversight from IT or data analysts, there is a greater chance that they will make mistakes in their analysis.
It can also be difficult to keep track of who is using which tool and how they are using it, which can add complexity to an already complex process.
Which of These Analysis Methods Describes Neural Computing?
The last phase of the Crisp-DM method is called the “Monitor and Control” phase. This phase is all about keeping track of your project and making sure that it stays on track. You’ll need to set up some kind of system to track your progress, and you’ll need to make sure that you’re regularly checking in on your project to see how it’s doing.
You might also want to consider setting up some sort of alerts or alarms so that if something goes wrong, you can be notified right away. And finally, you’ll need to create a plan for dealing with changes that come up during your project.
What Determines the Size of Words in a Word Cloud?
Word clouds are a fun and easy way to visualize data, but have you ever wondered how the size of words in a word cloud are determined? Here’s a quick breakdown!
The size of words in a word cloud is usually determined by two factors: frequency and importance.
Frequency is simply how often a word appears in the text – the more times a word appears, the larger it will be in the word cloud. Importance is a little bit more subjective, and can be determined by things like emotional weight or context. For example, if you were making a word cloud about a happy memory, words like “love” or “friendship” would likely be large, even if they don’t appear very often.
There are also some other factors that can influence the size of words in a word cloud, like font size or spacing between words. But at the end of the day, it’s usually frequency and importance that have the biggest impact. So next time you’re looking at a word cloud, take a closer look at how those sizes were determined – it might give you some insight into what the creator was trying to communicate!
Which of the Following is Not a Recognized Bi And Analytics Technique?
There are a lot of different techniques that can be used for bi and analytics. However, not all of them are recognized as official techniques. Here is a list of some of the more popular techniques, along with which ones are not recognized:
-Data mining: This is a process of extracting patterns from data. It is not recognized as an official technique by most organizations.
-Text analytics: This involves using natural language processing to analyze text data.
It is not recognized as an official technique by most organizations.
-Predictive modeling: This uses historical data to build models that predict future outcomes. It is generally recognized as an official technique by most organizations.
-Descriptive statistics: This summarizes data in a way that is easy to understand. It is generally recognized as an official technique by most organizations.
Which of the Following is Not a Component of a Kpi (Key Performance Indicator)?
There are a few different ways to measure performance, but key performance indicators (KPIs) are perhaps the most popular. They provide a way to track progress and compare it against predetermined goals. But what exactly is a KPI?
A key performance indicator is a metric that quantifies progress towards a specific goal. KPIs can be financial or non-financial, and they vary depending on the industry and company. Some common KPIs include things like revenue, profit margins, customer satisfaction levels, employee turnover rates, and safety records.
Not all metrics can be classified as KPIs, however. To be a true KPI, the metric must be tied directly to a specific goal. For example, if your goal is to increase sales by 10% this year, then tracking overall revenue would be a good KPI.
But if your goal is to improve customer satisfaction levels, then tracking how many complaints each department gets would not be an effective KPI because it doesn’t directly relate to customer satisfaction levels.
In short, a key performance indicator must meet three criteria: it must quantify progress towards a specific goal; it must be relevant to the business or industry; and it should be something that can be measured objectively. With those criteria in mind, let’s take a look at some examples of KPIs from different industries:
Manufacturing – On-time delivery rate, production costs per unit of output
Retail – Sales per square foot of store space
Banking – Deposits growth rate
Telecommunications – Average monthly revenue per user (ARPU)
Used to Explore Large Amounts of Data for Hidden Patterns to Predict Future Trends.
Data mining is the process of extracting valuable information from large data sets. It involves the use of sophisticated algorithms to uncover patterns and trends. Data mining can be used to predict future trends.
It can also be used to improve decision-making, marketing strategies, and operations.
One of the Goals of Business Intelligence is to
The goal of business intelligence is to provide insights that help businesses make better decisions. BI tools collect and analyze data from various sources to identify trends and patterns. This information can be used to improve marketing strategies, product development, and operations.
Business intelligence can give organizations a competitive advantage by helping them make better informed decisions. The right BI solution can help businesses save time and money, while also improving customer satisfaction.
Which of the Following is Not a Core Process Associated With Data Management?
There are a number of core processes associated with data management, but there is one that is often overlooked: data quality assurance. This process is critical to ensuring that your data is accurate and reliable, and it can help you avoid costly mistakes down the road.
Final Word
There are different types of neural networks, and each has its own advantages and disadvantages. So which of these analysis methods is best for you? The answer may surprise you.
In recent years, neural networks have become more popular as they have been shown to be very effective at training deep learning models. Deep learning is a type of machine learning that uses multiple layers of neural networks to learn from data. So which type of neural network is best for your problem?
It depends on the nature of the problem and the amount of data available. If you have a lot of data and the problem is not too complex, then a shallow neural network may be sufficient. Shallow neural networks only have a few layers of neurons and can be trained relatively quickly.
However, if the problem is more complex or if you don’t have enough data, then you will need to use a deep neural network. Deep neural networks can take longer to train but they can learn more complex patterns than shallow neural nets.